Keywords: markdown source, markdown parse, code block, parse list, parse tree, container fragment, container node, text fragment, text source, header fragment, header node, content list, paragraph node, character. Powered by TextRank.
There are a million markdown parsers for ready use but it's actually a fun challenge to roll out your own. I decided to do it when I realized that the swift markdown parser didn't provide the exact offsets of some of the tags within the source that I needed when converting into an AttributedString for a markdown editor.
There are a lot of approaches to parsing markdown but the simplest one is to break it down into
A block can be defined as a paragraph of text or \n\n with the exception of a fenced code block that starts with 3 backticks (unfortunately the parser I wrote doesn't yet support escaping a backtick character so I have to spell it out 😆).
The nice thing about markdown is for 99% of the cases you can process a line and don't have worry about continuity between lines (exception to this is lists and fenced code blocks) and a lot of special tagging can be inferred from the first character.
I'm going to take a look at each section for parsing one by one with some example pseudo-code.
To keep it simple, forget about parsing code fences (these make things a bit difficult because parsing stops when you are in a code fenced block and you can't split stuff into paragraph nodes). It's possible to have a lexer that iterates over all the blocks in the source by just splitting the source with the delimeter \n\n. Let's define an example markdown source we can work with and see this in action:
Example markdown source
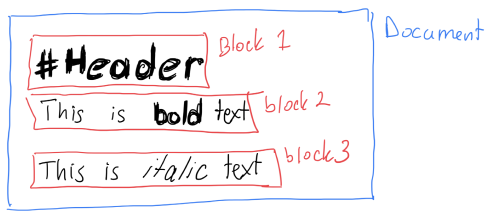
# My document This is an example document. With some `inline code` and **bold text** This is another paragraph.
When we talk about parsing we basically want to go from this flat text source to a tree structure which represents the document, much like the DOM represents an HTML document.
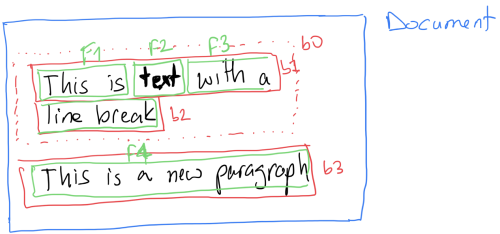
Once we have these "blocks" we can further break them down into lines. We need this to process things like lists and hard breaks. In the above example document source we would end up with 3 blocks
# My documentThis is an ...This is another ...After we have the lines, we can actually start looking at each line at a character level. Here we need to special case the first character as it can convey special meaning like a header or a list item. The rest of the characters we can just iterate over and process and generate fragments like inline code or bold text based on the markdown syntax rules. Anything that doesn't match a rule is assumed to be a text fragment. The scanners for each tag would try to parse a fragment and return nil if they fail. It's totally possible that the author started an inline code tag with ` but never closed it. In this case the scanner should return nil so that other scanners get a chance to parse it or it can be considered as a text fragment.
The tricky part is how do we represent the nodes in a tree and how to handle embedded items. What do I mean by embeded? Something like the following
<ul> <li><strong>Hello</strong></li> </ul>
In this tree structure the ul tag is the parents and it has 1 child: <li> tag which is self also has a child.
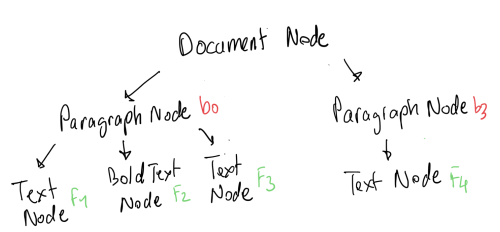
The idea here is that some of the nodes are container nodes and they are only there to contain other nodes. Remember that text is also represented as a node, so something like
- this is **bold**
which in HTML speak would be
<ul> <li>this is <strong>bold</strong></li> </ul>
in our parse tree would look like
ListNode(
BulletListItemNode(
TextNode("this is "),
BoldTextNode("bold")
)
)In this example the ListNode and BulletListItemNode are container nodes and the others are regular nodes.
As we figure out the fragments, we append everything we find to a list. Then when it's time to parse this into a tree we reverse the list and start processing it. It's probably easiest to go with another example here:
# this _is_ a header
We expect our parse tree to be
HeaderNode(TextNode("this "), ItalicTextNode("is"), TextNode(" a header"))So when we lexed this out list became
[FragmentHeader, FragmentText("this "), FragmentItalicText("is"), FragmentText(" a header")]It's somewhat close to what we want, but not quite. The Header isn't encapsulating the other items. So when we parse this we reverse the list
[FragmentText(" a header"), FragmentItalicText("is"), FragmentText("this "), FragmentHeader]Next we need to lists to track the current content and the containers for the content.
content = [] result = []
The idea is that if we see a container fragment (like header) we'll append the contents list to the children of that container node, other wise we'll prepend a node for that fragment to the contents list.
So first up is FragmentText("a header"). This is not a container node, so it get prepended to the content list. The reason we need to prepend is that we are processing the fragments in reverse order. To kind of like it's reversed twice to make it the correct resulting order.
Next up FragmentItalicText("is"). The same as before and for the next fragment too. So out contents list is now
contents = [TextNode("this "), ItalicTextNode("is"), TextNode(" a header")]Now we get to the header fragment which is a container. So we create a HeaderNode which is a container node and assign the current value of content to it's children and clear the content list.
h = HeaderNode(children: contents) result.append(h) contents = []
Now our state is the following
result = [HeaderNode(children: [TextNode("this "), ItalicTextNode("is"), TextNode(" a header")])]
contents = []We are done so we can return result which is what we wanted to get. The header node is encapsulating the other nodes.
This was a pass at the fundamentals of how a markdown parser works. In a new blog post, I will write about how to parse lists and fenced code blocks which pose different problems. Namely, lists need a way of looking at what the previous block was and fenced code blocks need a way so signal to the lexer that the source should be copied verbatim and not processed.
1021 words
First published on 2024-02-05
Generated on 5 Apr 2026 at 5:49 AM
Mobile optimized version. Desktop version.