Keywords: current character pointer, pgn move, token return, input character, pointer node, current token, previous node, previous token, tree, variation, lexer, stack, antlr. Powered by TextRank.
PGN files are the standard way chess games are transmitted across the net. So any chess program that needs to replay or process a game needs to be able to read the PGN format. There are very many different PGN parsers around in different programming languages. Most of them try to process the PGN using regexes, or just reduce the data to the main line moves, event discarding the comments and annotations. This may be OK if you are processing the game for purposes of machine consumption as the comments don't mean anything to a machine but I wanted to write a parser that preserves the comments and the recursive variations.
So the first part of any non trivial parser is going to be a "Lexer" that tokenizes the input. Check out the PGN formal grammar for ANTLR (https://github.com/antlr/grammars-v4/blob/master/pgn/PGN.g4) that has a details. It's a good idea to use this ANTLR code to if you don't want to fiddle with insides of a parser.
So the lexer will consume the input character by character creating tokens from this input. Here is the token class that I used:
public class Token
{
public string Type { get; }
public string Value { get; }
public const string MoveNumber = "MoveNumber";
public const string SAN = "SAN";
public const string Comment = "Comment";
public const string EOF = "EOF";
public const string Result = "Result";
public const string Header = "Header";
public const string NAG = "NAG";
public const string LPAREN = "LPAREN";
public const string RPAREN = "RPAREN";
public Token(string type, string value)
{
Type = type;
Value = value.Replace("\n", "");
}
public override string ToString()
{
return "Token " + Type + " " + Value;
}
}We need to treat the left parenthesis and the right one as individual tokens as they will have a special meaning when we are creating the syntax tree.
Diving deeper into the Lexer:
private int _position = 0;
private Char _currentChar;
private string _text;
private Boolean _lexingDone;
public PgnLexer(string pgnText)
{
_text = pgnText;
if (_text.Length > 0)
_currentChar = _text[_position];
}pretty simple, we need to do some book keeping - the current character pointer and the input data is stored.
private void Advance()
{
_position += 1;
if (_position >= _text.Length)
{
_lexingDone = true;
}
else
{
_currentChar = _text[_position];
}
}each time we consume a character the Advance() method will increment the pointer and check if all the input has been consumed.
private void SkipWhitespace()
{
while (!_lexingDone &&
(Char.IsWhiteSpace(_currentChar) ||
_currentChar == '.' ||
_currentChar == '\n'))
{
Advance();
}
}Some PGN files are transcribed by humans and contain multiple whitespaces, some are computer programs inserting optional white spaces for better readability etc. The '.' character is also treaded as a white space as the move indication "2... c4" has multiple '.' characters that we'll skip.
public Token GetNextToken()
{
string result = "";
while (!_lexingDone)
{
//result += _currentChar;
if (_currentChar == '(')
{
Advance();
SkipWhitespace();
return new Token(Token.LPAREN, result);
}
if (_currentChar == ')' && result.Trim().Equals(""))
{
Advance();
SkipWhitespace();
return new Token(Token.RPAREN, result);
}
if (_currentChar == '[')
{
Advance();
while (_currentChar != ']')
{
result += _currentChar;
Advance();
}
Advance();
SkipWhitespace();
return new Token(Token.Header, result);
}
if (_currentChar == '.')
{
SkipWhitespace();
return new Token(Token.MoveNumber, result);
}
if (_currentChar == '{')
{
while (_currentChar != '}')
{
Advance();
result += _currentChar;
}
Advance();
return new Token(Token.Comment, result.Replace("{","").Replace("}",""));
}
if ( (_currentChar == '\n' ||_currentChar == ' ' || _currentChar == ')') && !result.Trim().Equals(""))
{
SkipWhitespace();
result = result.Trim().Replace(" ", "").Replace("\n", "");
if (result.Equals("1-0") || result.Equals("0-1") || result.Equals("1/2-1/2") || result.Equals("*"))
return new Token(Token.Result, result);
if (result.StartsWith("$"))
{
return new Token(Token.NAG, result);
}
return new Token(Token.SAN, result);
}
result += _currentChar;
Advance();
}
if (result.Equals(""))
return new Token(Token.EOF, "");
return new Token(Token.Result, result);
}this is the real part that does the tokenization. Parenthesis type characters are consumed until the matching one is found, otherwise we consume until we reach a character that terminates a move element and return the resulting token. If we have consumed all the input we return the game result. Some PGN files may have extra white spaces at the end, so we return an EOF token if that's the case.
Now that we can fetch the tokens from the file, we need to construct a tree representing the moves, comments, variations etc. in the PGN file.
private readonly PgnLexer _lexer;
private Token _currentToken;
public PgnParser(PgnLexer lexer)
{
_lexer = lexer;
_currentToken = lexer.GetNextToken();
}We need to track the currentToken and pass a reference to our lexer to fetch more tokens.
This method will "eat" through the tokens and allow us to move forward in the processing:
private void Eat(string tokenType)
{
if (_currentToken.Type.Equals(tokenType))
{
_currentToken = _lexer.GetNextToken();
}
else
{
throw new Exception("Invalid syntax");
}
}Take for example this made up PGN move text:
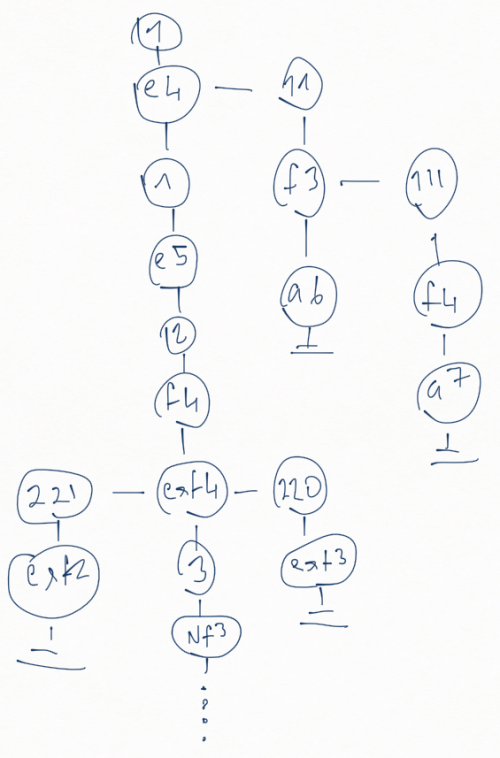
"1.e4 (11. f3 (111. f4 a7) a6) 1... e5 2.f4 exf4 (220... exf3) (221... exf2) 3.Nf3 g5 4.h4 ..."
(The move numbers are not correct even the moves may be illegal but the purpose is to illustrate the tree that we are aiming to build.)
We want to transform this into the following tree:
All vertical connections are the next node connections and the horizontal connections are the variation connections. So "e4" move spawns a variation that it self has an embedded variation (hence the name recursive variations). The move "exf4" spawns 2 variations at this move.
So we start with a method to transform the current token to a node:
private Node Element()
{
if (_currentToken.Type.Equals(Token.SAN))
{
Node node = new SanNode();
node.Value = _currentToken.Value;
return node;
}
if (_currentToken.Type.Equals(Token.Result))
{
return new ResultNode();
}
if (_currentToken.Type.Equals(Token.MoveNumber))
{
var node = new MoveNumberNode();
node.Value = _currentToken.Value;
return node;
}
if (_currentToken.Type.Equals(Token.Header))
{
var node = new HeaderNode();
node.Value = _currentToken.Value;
return node;
}
if (_currentToken.Type.Equals(Token.Comment))
{
var node = new CommentNode();
node.Value = _currentToken.Value;
return node;
}
{
var node = new NullNode();
return node;
}
}So first the code to build the tree
private Stack<Node> _stack = new Stack<Node>();
private Node BuildTree(Node node)
{
Node root = node;
Node prevNode = node;
while (true)
{
Console.WriteLine(_currentToken);
if (_currentToken.Type.Equals(Token.EOF))
{
return null;
}
var currentNode = Element();
if (currentNode.GetType() == typeof(ResultNode))
{
Eat(_currentToken.Type);
prevNode.Next = currentNode;
return root;
}
if (_currentToken.Type.Equals(Token.LPAREN))
{
_stack.Push(prevNode);
prevNode.Next = currentNode;
prevNode = prevNode.Next;
}
else if (_currentToken.Type.Equals(Token.RPAREN))
{
prevNode.Next = currentNode;
var t = _stack.Pop();
t.Variations.Add(t.Next);
prevNode = t;
prevNode.Next = null;
}
else
{
prevNode.Next = currentNode;
prevNode = prevNode.Next;
}
Eat(_currentToken.Type);
}
}The algorithm is as follows:
So if we walk through an example move text of "1. e4 (11. f3 a7) 1...e5 2.Nf3" this is node state and stack state just before the RPAREN:
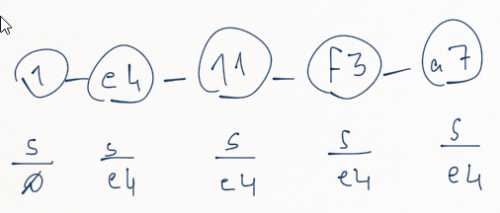
When we process the RPAREN we will pop the "e4" node from the stack, move the next pointers nodes to the variations, delete the next pointer and set the previous node to e4 and continue processing.
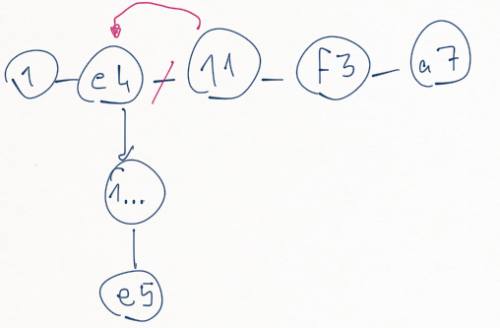
There the tree with embedded variations. The code I use actually takes care of further evaluating the tree into the chess model I use in the application by checking if the move in the PGN is valid, and adding the comments to the move etc. But this is the basics of parsing the PGN file.
1355 words
Powered by TF-IDF/Cosine similarity
First published on 2017-03-01
Generated on 11 Aug 2025 at 12:22 PM
Mobile optimized version. Desktop version.